IndexBr
Conjunto de documentações relacionadas ao sistema IndexBr
Monitoramentos
Tipos de consulta
- must: A consulta deve aparecer nos documentos retornados e contribui para a pontuação.
- filter: A consulta deve aparecer nos documentos retornados mas não contribui para pontuação. Filtros são executados antes das demais consultas reduzindo o escopo da busca.
- should: São opcionais mas aumentam a pontuação dos documentos. O Index utiliza a configuração de
match mínimo = 1para evitar que consultas should isoladas retornem resultados inválidos. - must not: A consulta não deve aparecer nos documentos retornados pela busca.
Sintaxe das consultas
As consultas dos monitoramentos no sistema IndexBr utilizam a sintaxe "query string" do Elasticsearch para buscar artigos pelo conteúdo de seu título e texto.
Consultas são compostas por tokens e operadores.
Toda consulta de texto simples é interpretada como uma sequência tokens separados por espaços:
Tribunal de Justiça
Caso não haja operador especificado os tokens serão interligados com o operador padrão (OR). Tornando a consulta anterior equivalente a:
Tribunal OR de OR Justiça
Matches: qualquer documento que contenha ao menos uma das três palavras
Com o uso de aspas (") é possível interpretar uma frase como um token único preservando a ordem das palavras durante a busca:
"Tribunal de Justiça"
Wildcards (Coringas)
?para um caratere*para zero ou mais caracters
Ex.: deputad?
Matches: deputado, deputada
Ex.: flor*
Matches: flor, florido
Busca por proximidade
O operador ~ permite busca de proximidade por distância de edição.
A distância de edição é definida pela quantidade de mudanças de um caracter para transformar um termo em outro. Essas mudanças podem incluir as seguintes operações:
- Trocar um caractere (gato → gado)
- Remover um caractere (preto → reto)
- Inserir um caractere (som → soma)
- Transpor dois caracteres adjacentes (apto → pato)
Ex.: gato~ pato~ orta~
O valor padrão de distância é de 2 caracteres mas pode ser redefinido após o operador:
Ex.: gato~1
Quando aplicado a frases o operador ~ permite que as palavras apareçam separadas ou em ordem diferente nos resultados da busca. A distância de edição passa a ser relativa as palavras e não mais aos caracteres.
Ex.: "gato preto"~5
Matches: gato preto, gato de rua preto
Nota: A busca por proximidade não pode ser usada em conjunto com wildcards
Boosting
O operador de boost ^ pode ser usado para aumentar a relevância de um termo.
Ex.: gato^2 preto
O valor padrão de impulsionamento é 1 mas pode ser definido como qualquer decimal positivo. Valores entre 0 e 1 reduzem a relevância.
O impulsionamento também pode ser aplicado a frases e grupos:
Ex.: "gato preto"^2, (gato preto)^4
Operadores booleanos
Operadores suportados: OR, AND, NOT
Termos e operadores podem agrupados com o uso de parênteses:
Ex.: ("Ministério Público da Bahia" OR "MP-BA") AND Trânsito
Sintaxe alternativa
O Elasticsearch oferece uma sintaxe simplificada para expressar as relações booleanas baseada em prefixos:
+para termos que devem aparecer na busca-para termos que não devem aparecer na busca- termos sem prefixo utilizam o operador padrão (
OR) e portanto são opcionais na busca
O exemplo anterior pode ser reescrito utilizando operadores prefixos:
Ex.: +("Ministério Público da Bahia" "MP-BA") +Trânsito
Busca excluindo o termo Trânsito:
Ex.: +("Ministério Público da Bahia" "MP-BA") -Trânsito
Espaçamento
Os termos e frases podem ser separados por espaços ou quebras de linha sem qualquer prejúizo a semântica da consulta. A formatação fica a preferência do usuário:
+("Ministério Público da Bahia" "MP-BA") +Trânsito
ou
+("Ministério Público da Bahia"
"MP-BA")
+Trânsito
Transcrições
Fluxo de integração
A integração de transcrições no sistema IndexBr ocorre de acordo com o seguinte fluxo:
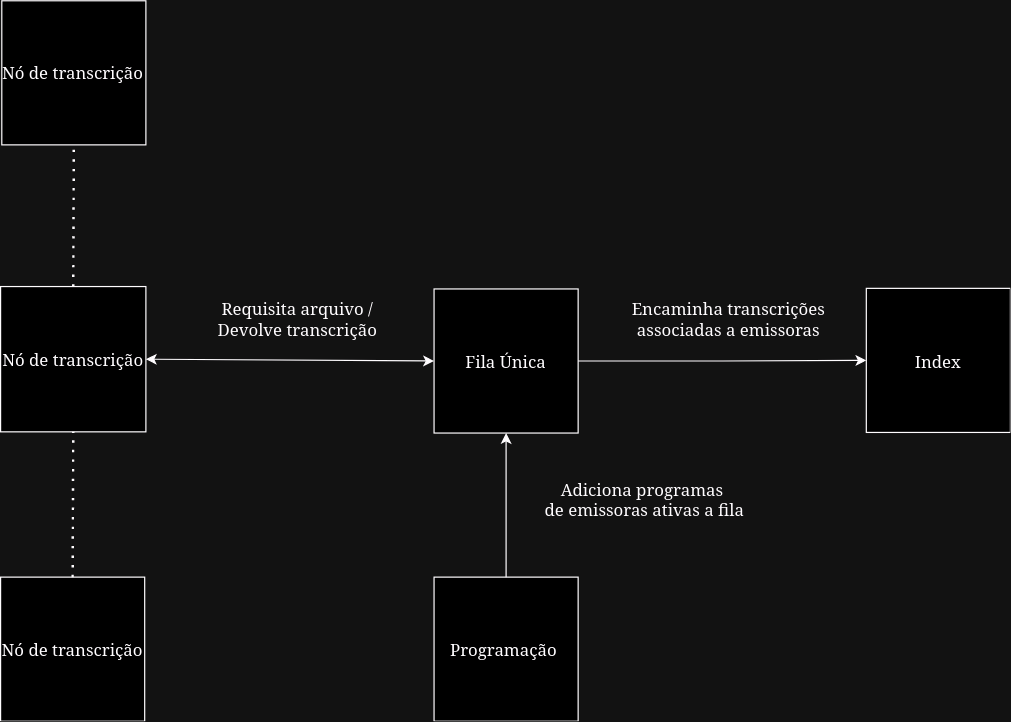
- Os arquivos de programas das emissoras ativas no dashboard de programação são adicionados a fila única
- Os nós de transcrição adquirem arquivos da fila para processamento e devolvem a transcrição para a fila
- Ao receber uma transcrição associada a uma emissora a fila faz o encaminhamento para o sistema index
Consumo de transcrições a partir do Index
Uma vez no sistema Indexbr as transcrições do dia podem ser consultadas por meio de monitoramentos por utilizando endpoint:
GET /v1/monitorings/{id}/transcriptions
Monitoramentos podem ser criados no dashboard do index ou também via api:
POST /v1/monitorings
{
"name": "my_monitoring",
"queries": [
{
"condition": "must | must_not | filter | should",
"name": "my_query",
"query": "words to search"
}
]
}
Artigos produzidos a partir das transcrições podem ser integrados ao sistema utilizando a rota:
POST /v1/articles
{
"author": "That Journalist",
"extracted_date": "2024-06-05T00:00:00Z",
"media_type": "radio | tv | web | journal | social",
"origin": "Fonte de captura do artigo",
"published_date": "2024-06-05T00:00:00Z",
"setor_grid": "",
"subtitle": "My subtitle",
"text": "This article is awesome, trust me!",
"title": "My title",
"url": "https://news.frommytown.com.br/news/4321?rergs=rurgs#at_anchor"
}
Uma descrição mais abrangente dos endpoints expostos pelo sistema index pode ser encontrada na documentação da api.
Formato das transcrições
Transcrições são armazenadas seguindo o formato do exemplo:
{
"_index": "transcriptions",
"_type": "_doc",
"_id": "2IxC6Y8BQ6m1DA3NxK89",
"_score": 0.0,
"_source": {
"transcription": "metade do gás carbônico que a gente lançou atmosfera em grossa camada e faz com que a terra fique mais instituições fique mais verdade não muito se falou também sobre como",
"vtt": "none",
"srt": "none",
"json_file": "[{\"alternatives\": [{\"text\": \"metade do g\\u00e1s carb\\u00f4nico que a gente lan\\u00e7ou atmosfera em grossa camada e faz com que a terra fique mais institui\\u00e7\\u00f5es fique mais verdade n\\u00e3o muito se falou tamb\\u00e9m sobre como\", \"words\": [{\"text\": \"metade\", \"score\": \"0.31\", \"start_time\": \"0.36\", \"end_time\": \"0.93\"}, {\"text\": \"do\", \"score\": \"0.94\", \"start_time\": \"0.93\", \"end_time\": \"1.08\"}, {\"text\": \"g\\u00e1s\", \"score\": \"1.00\", \"start_time\": \"1.08\", \"end_time\": \"1.31\"}]",
"tsv": "none",
"duration": 300.04245,
"original_file_path": "/mnt/rtv-index/midiaclip/rtv-servers/mdc-rtvsrv02/tvs/local/salvador/tvband-sd/20240605/tvband-sd_2024-06-05_13-18-16.mp4",
"original_file_url": "018fe941-f409-76ba-b7fb-e3a73d63a63a",
"datetime": "2024-06-05T13:18:16Z",
"server_file": "/mnt/rtv-index/midiaclip/rtv-servers/mdc-rtvsrv02/tvs/local/salvador/tvband-sd/20240605/tvband-sd_2024-06-05_13-18-16.mp4",
"broadcaster": {
"id": 432,
"name": "TV BAND",
"broadcaster_type": "Tv",
"origin": "/mnt/rtv-index/midiaclip/rtv-servers/mdc-rtvsrv02/tvs/local/salvador/tvband-sd"
}
}
}
Nexus
Infraestrutura
O Nexus, web crawler da index, segue a infraestrutura descrita no diagrama abaixo:
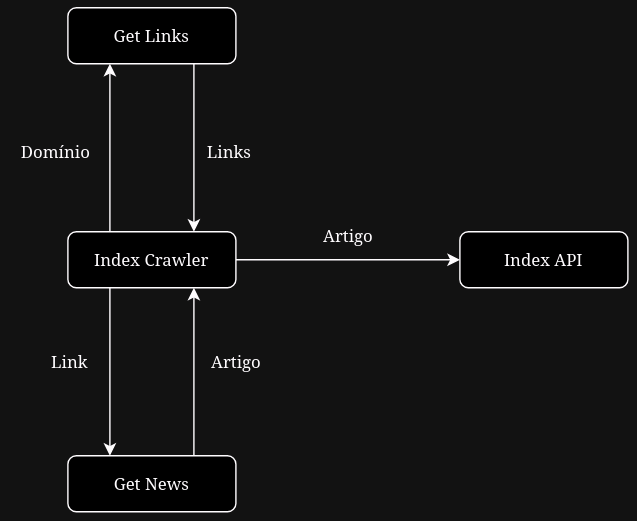
O Nexus gerencia uma fila de domínios cadastrados e se comunica com nós de trabalho de maneira que o processo de obter um artigos é divido em duas etapas:
- Os nós de coleta de links (Get Links) solicitam um domínio para a fila do Nexus e devolvem uma lista de links encontrados no site que é armazenada no banco de dados do Nexus
- Os nós de coleta de artigos (Get News) solicitam links para o Nexus e devolvem artigos quando a extração é bem sucedida
Get Links
Novos links para os domínios cadastrados são buscados a cada ciclo da rotina do Nexus (6h).
A extração pode ocorrer via sitemap ou fullcrawler:
- Sitemap: busca o mapeamento de links fornecido pelo site no arquivo robots.txt
- Fullcrawler: Faz o download da home do site e extrai todos os links
Caso não definido no domínio o método será inferido com a tentaiva de utilizar sitemap e em caso de falha utilizar fullcrawler.
Get News
Os nós de extração de artigos recebem links e classificam o conteúdo da página de maneira que somente com a presença de título, texto e data de publicação um novo artigo é produzido caso contrário um erro é reportado ao Nexus.
Index Users
O módulo Index Users centraliza a autenticação e autorização de todos os módulos e serviços da index.
Os usuários index são atrelados a tenants e possuem perfis que definem seu nível de permissão e acesso nos sistemas da index.