Nexus
Infraestrutura
O Nexus, web crawler da index, segue a infraestrutura descrita no diagrama abaixo:
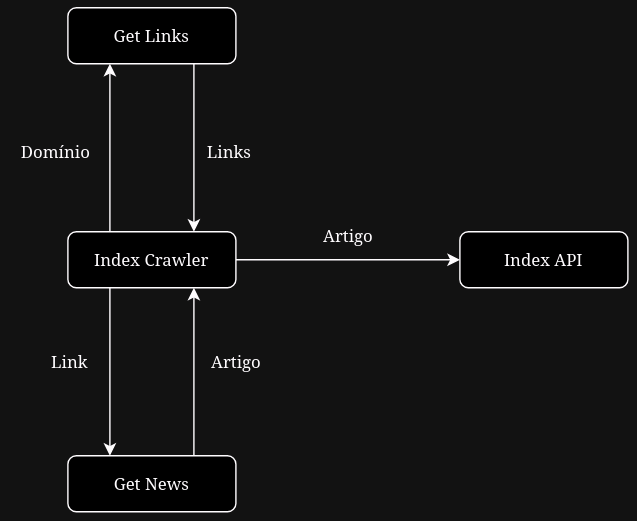
O Nexus gerencia uma fila de domínios cadastrados e se comunica com nós de trabalho de maneira que o processo de obter um artigos é divido em duas etapas:
- Os nós de coleta de links (Get Links) solicitam um domínio para a fila do Nexus e devolvem uma lista de links encontrados no site que é armazenada no banco de dados do Nexus
- Os nós de coleta de artigos (Get News) solicitam links para o Nexus e devolvem artigos quando a extração é bem sucedida
Get Links
Novos links para os domínios cadastrados são buscados a cada ciclo da rotina do Nexus (6h).
A extração pode ocorrer via sitemap ou fullcrawler:
- Sitemap: busca o mapeamento de links fornecido pelo site no arquivo robots.txt
- Fullcrawler: Faz o download da home do site e extrai todos os links
Caso não definido no domínio o método será inferido com a tentaiva de utilizar sitemap e em caso de falha utilizar fullcrawler.
Get News
Os nós de extração de artigos recebem links e classificam o conteúdo da página de maneira que somente com a presença de título, texto e data de publicação um novo artigo é produzido caso contrário um erro é reportado ao Nexus.